Une langue absente des données est souvent absente de l'IA : réflexion autour de l'initiative Komor-IA
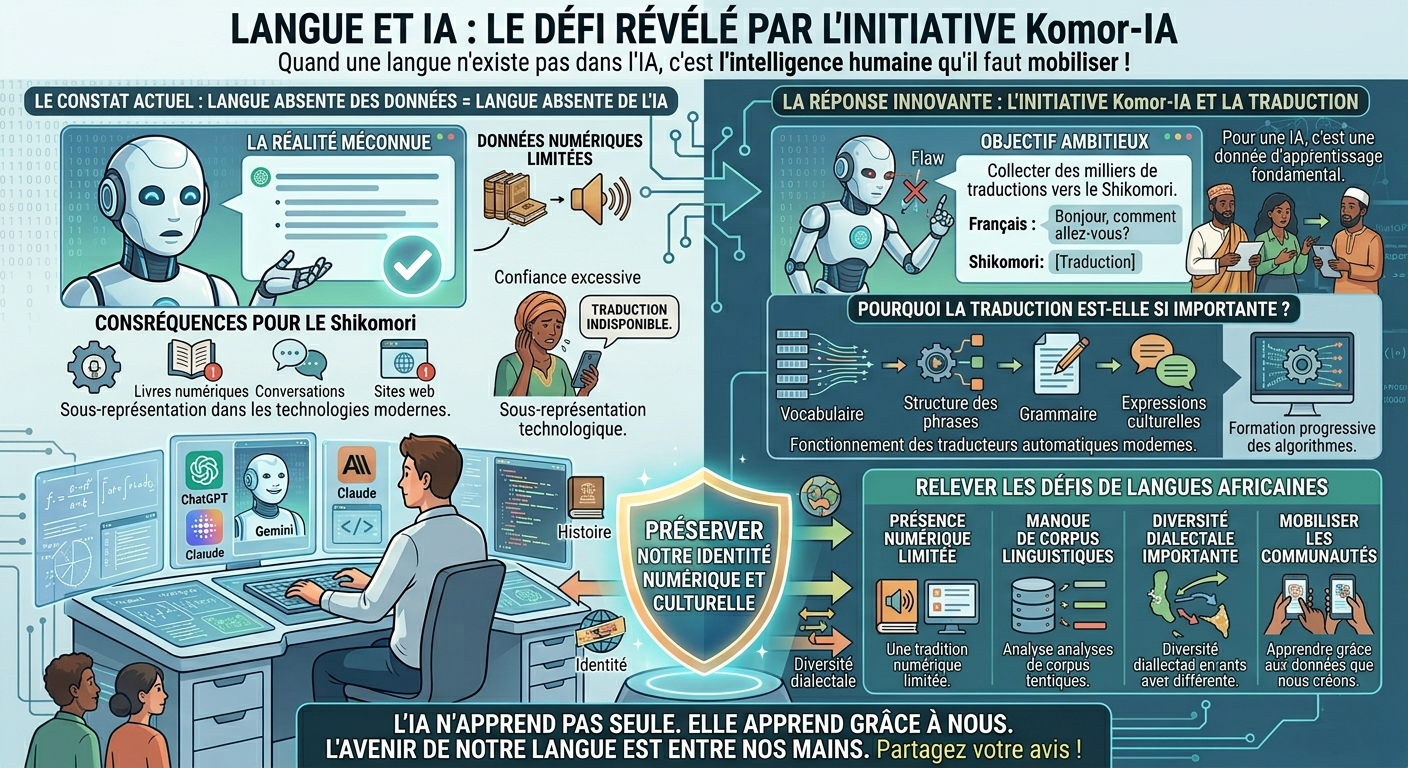
Récemment, le projet Komor-IA a annoncé le lancement d'une campagne de traduction vers le Shikomori (la langue Comorienne), une langue parlée par environ 800 000 personnes. L'objectif est ambitieux : collecter des milliers de traductions afin d'entraîner des modèles d'intelligence artificielle capables de comprendre et de parler cette langue.
En tant qu'étudiant en Intelligence Artificielle et Sciences des données, une publication récente de Komor-IA a particulièrement retenu mon attention.
L'initiative vise à collecter des traductions du français vers le Shikomori afin de développer des modèles capables de comprendre et de générer cette langue.
Derrière cette annonce se cache une réalité fondamentale de l'intelligence artificielle moderne :
Les modèles d'IA ne deviennent pas performants grâce à leur architecture uniquement, mais surtout grâce aux données sur lesquelles ils sont entraînés.
Les modèles de langage apprennent à partir des données
Lorsqu'on utilise des outils comme ChatGPT, il est facile d'avoir l'impression qu'ils « comprennent » les langues de manière naturelle.
En réalité, les modèles de langage fonctionnent différemment.
Ils apprennent des relations statistiques entre les mots, les phrases et les contextes à partir d'immenses corpus de données textuelles.
Plus une langue est représentée dans ces données, plus le modèle peut apprendre :
- son vocabulaire ;
- sa grammaire ;
- ses expressions idiomatiques ;
- ses structures syntaxiques.
À l'inverse, lorsqu'une langue est peu présente dans les corpus d'entraînement, les performances du modèle diminuent considérablement.
Pourquoi la collecte de traductions est-elle importante ?
La campagne de Komor-IA repose sur un principe central du traitement automatique des langues (NLP) : l'apprentissage supervisé.
Prenons un exemple simple :
Français :
Je vais au marché.
Shikomori (Ngazidja) :
Ngamwendo ho chindoni.
Pour un humain, il s'agit simplement d'une traduction.
Pour un modèle d'IA, il s'agit d'une paire d'apprentissage.
Des milliers, voire des millions de paires similaires permettent au modèle d'apprendre les correspondances entre deux langues.
Ces données servent ensuite à entraîner :
- des systèmes de traduction automatique ;
- des modèles conversationnels ;
- des systèmes de reconnaissance vocale ;
- des outils de synthèse vocale.
En sciences des données, on entend souvent une phrase :
Garbage In, Garbage Out (GIGO).
Autrement dit, même le meilleur algorithme produira de mauvais résultats si les données d'entrée sont insuffisantes ou de mauvaise qualité.
Le véritable défi : les langues à faibles ressources
Dans le domaine du NLP, on parle souvent de langues à faibles ressources (low-resource languages).
Il s'agit de langues disposant de peu de ressources numériques :
- corpus textuels limités ;
- peu de traductions alignées ;
- manque de jeux de données annotés ;
- faible présence sur le web.
C'est précisément là que se situe l'un des plus grands défis de l'IA moderne.
Aujourd'hui, les modèles les plus performants bénéficient de milliards de tokens d'entraînement, principalement issus de langues fortement représentées comme l'anglais.
Les langues moins numérisées risquent alors d'être sous-représentées dans les systèmes d'IA du futur.
Pourquoi les données sont plus importantes que le modèle lui-même
En intelligence artificielle, il est tentant de se concentrer sur les architectures les plus récentes : Transformers, LLMs ou modèles multimodaux.
Pourtant, l'expérience montre souvent qu'une amélioration des données produit davantage de gains qu'une simple augmentation de la complexité du modèle.
La qualité des données influence directement :
- la précision ;
- la robustesse ;
- la généralisation ;
- la réduction des biais.
Un modèle entraîné sur des données insuffisantes ou biaisées reproduira naturellement ces limitations.
Ainsi, la création de corpus linguistiques devient une étape stratégique pour le développement d'IA inclusives.
La stratégie de Komor-IA : construire un corpus linguistique collaboratif
L'approche adoptée par Komor-IA repose sur une stratégie largement utilisée dans le domaine du traitement automatique des langues (NLP) : la création collaborative de corpus linguistiques.
Concrètement, la plateforme demande aux locuteurs natifs de traduire des articles du français vers différentes variantes du shikomori. Chaque traduction validée vient enrichir une base de données linguistique qui pourra ensuite être utilisée pour entraîner des modèles d'intelligence artificielle.
Le processus mis en place est particulièrement intéressant d'un point de vue scientifique :
- les utilisateurs choisissent un article à traduire ;
- ils sélectionnent leur dialecte ;
- la plateforme sauvegarde automatiquement leur progression ;
- les traductions soumises sont ensuite vérifiées par une équipe de linguistes avant d'être intégrées au corpus final.
Cette étape de validation est essentielle.
En apprentissage automatique, la qualité des données est souvent plus importante que leur quantité. Un corpus mal annoté ou contenant des erreurs peut introduire des biais et dégrader les performances du modèle.
L'initiative de Komor-IA adopte ainsi une approche dite human-in-the-loop, où les humains participent directement à la création et à la validation des données utilisées par l'IA. Cette stratégie est couramment employée dans les grands projets d'annotation linguistique et de développement des modèles de langage modernes.
Un autre aspect particulièrement intéressant est la prise en charge des quatre variantes du shikomori : Shingazidja, Shindzuani, Shimwali et Shimaore. Cette diversité linguistique permet de mieux représenter les spécificités régionales et d'éviter qu'un seul dialecte ne domine l'apprentissage du modèle.
En réalité, la plateforme ne collecte pas simplement des traductions.
Elle construit progressivement l'une des ressources les plus précieuses en intelligence artificielle : des données de qualité, produites et validées par la communauté elle-même.
Au-delà de la traduction : construire un écosystème numérique
Créer un corpus de traduction n'est souvent que la première étape.
Ces ressources peuvent ensuite être utilisées pour développer :
- des assistants conversationnels ;
- des traducteurs automatiques ;
- des outils éducatifs ;
- des systèmes de reconnaissance vocale ;
- des applications d'accessibilité.
Autrement dit, chaque phrase traduite aujourd'hui peut devenir une brique technologique pour les applications de demain.
Voici le lien pour la contribution : https://www.komor-ia.com/contribution
https://www.facebook.com/share/p/1EJTkR1aiP/
Une réflexion pour l'avenir
L'initiative de Komor-IA illustre parfaitement une réalité souvent oubliée :
L'avenir de l'intelligence artificielle ne dépend pas uniquement des algorithmes, mais aussi de notre capacité à produire et préserver des données de qualité.
À l'heure où les grands modèles de langage transforment notre manière d'interagir avec l'information, une question mérite d'être posée :
Comment garantir que les langues moins représentées ne soient pas laissées de côté dans la révolution de l'IA ?
Et vous, pensez-vous que la diversité linguistique devrait devenir une priorité dans le développement des futurs systèmes d'intelligence artificielle ? Partagez votre point de vue en commentaire.
Vous avez aimé ?
Likez et partagez !
Commentaires (0)
Soyez le premier à commenter !
Laisser un commentaire